
[딥러닝1] 딥러닝에서 학습은 어떻게 일어날까? (딥러닝의 기본 원리)
들어가기에 앞서…
- 이 글은 딥러닝을 처음 접하시는 분들을 위해 개념적인 내용을 담았습니다. 배경 지식 없이도 내용을 이해할 수 있도록 도와드리겠습니다.
- 일부 용어에 있어서 한국어로 번역된 것보다 원어를 사용하는 것을 지향합니다. 이해해 주시면 감사하겠습니다!
- 잘못된 내용이 있으면 언제든 피드백 주세요! 빠르게 고치도록 하겠습니다.
목차
순서대로 읽으시는 것을 추천드립니다!
- ‘인공 신경망’과 ‘신경망’ 👉바로가기
- 퍼셉트론 (Weight & Activation) 👉바로가기
- 다중 퍼셉트론 👉바로가기
- Layer 👉바로가기
- 학습이란? Weight를 찾아가는 과정이다! 👉바로가기
- Forward-propagation과 Loss 👉바로가기
- Gradient와 Back-propagation 👉바로가기
- 정리하자면… 👉바로가기
1. ‘인공 신경망’과 ‘사람의 신경망’
딥러닝 구조는 사람의 뇌 속의 신경 세포의 구조를 모델화 한 것이라고 합니다. 딥러닝 구조를 흔히 ‘인공 신경망(artifical neural network)’ 라고도 하죠.
그렇다면 둘은 어떤 공통점이 있는 것일까요? 아래 그림은 사람의 신경망과 딥러닝의 신경망을 나타낸 것입니다.
사람의 신경세포(뉴런)는 복잡하게 서로 연결되어 있습니다. 사람한테 외부 자극(정보)이 들어오면 전기 신호로 변환된 후 전기 신호가 수많은 뉴런 사이를 이동하게 됩니다. 이때 한 뉴런에서 출력된 전기 신호는 다른 뉴런의 입력으로 들어가게 돼요.
딥러닝에서도 마찬가지입니다. 특정 행동을 하는 뉴런 하나하나가 서로 복잡하게 연결되어 있습니다. 마찬가지로 한 뉴런에서 계산된 출력값이 다른 뉴런의 입력값이 되죠. 여기서 세포, 즉 뉴런 하나가 어떤 역할을 하는지는 다음 파트에서 설명 하겠습니다.
2. 퍼셉트론 (Weight & Activation)
가장 일반적인 딥러닝 모델을 흔히 MLP (Multi Layer Perceptron) 이라고 합니다. 해석하자면 “퍼셉트론이 여러 층으로 이루어진 구조” 입니다. 먼저, 딥러닝에서의 퍼셉트론에 대응하는 사람의 뉴런(신경세포)에서의 연산을 간단히 알아봅시다.
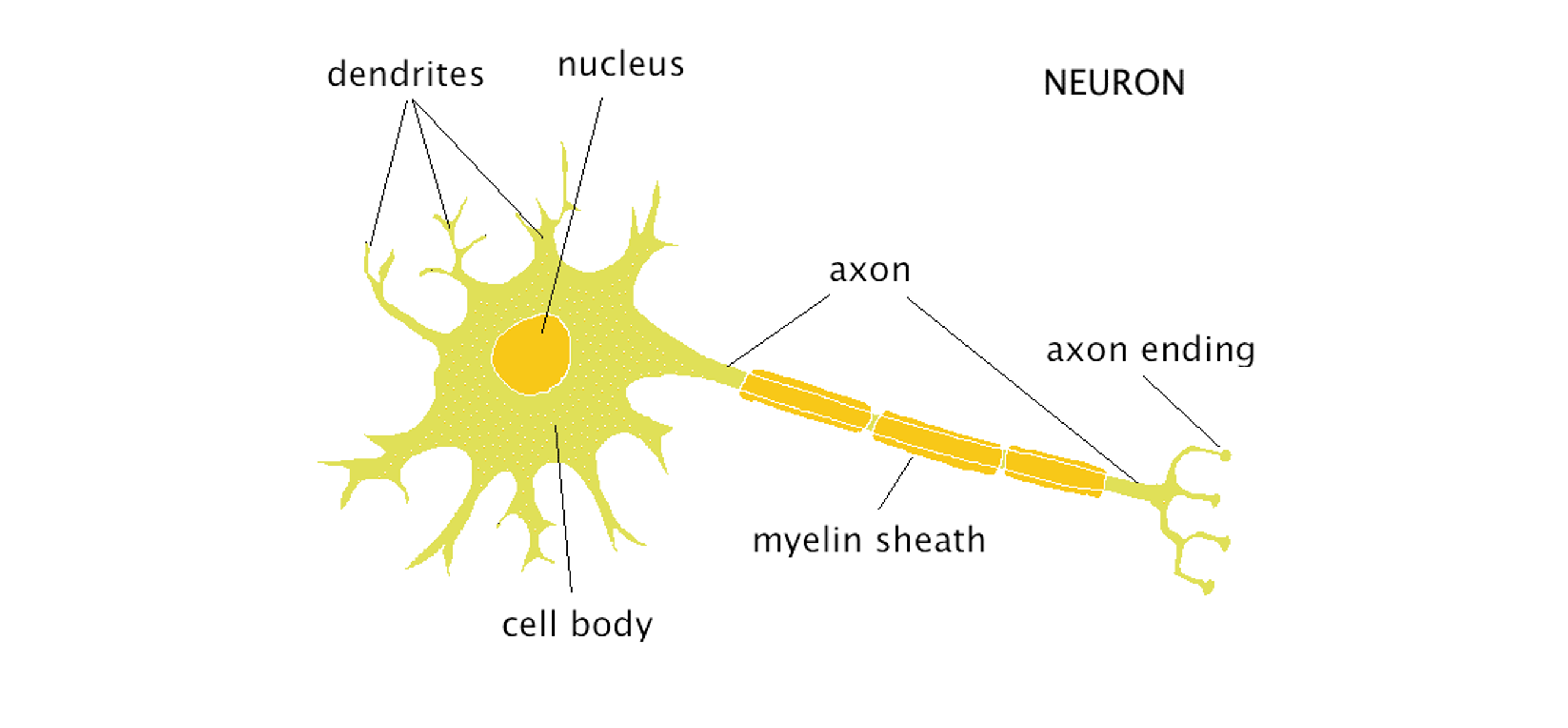
생명과학 시간에 수상돌기, 축삭돌기, 가지돌기.. 등등 재미있는 단어를 들어본 적이 있으실 텐데요, 신경 세포의 구조를 설명하는 단어입니다. 신경 세포는 (그림2)의 Dendrites(수상돌기)를 통해 전달받은 신호가 특정 임계점 이상이 올때 Axon(축삭돌기)를 통해 다음 신경 세포로 전달합니다. 딥러닝 구조에서 뉴런의 역할도 이것과 비슷하다고 할 수 있습니다.

퍼셉트론은 신경세포의 동작 과정을 통계학적으로 모델링한 알고리즘입니다. (그림3)을 보며 이해해 봅시다. 하나의 퍼셉트론은 여러 Input을 가질 수 있습니다. (그림3)에서 🍎, 🍏, 🍊는 들어오는 Input을 나타냅니다. 이러한 Input들에게 첫번째로 Weighted Sum(가중합)을 구하는 연산이 적용됩니다. 🍎(첫번째 input)에는 $ w_1 $, 🍏(두번째 input)에는 $ w_2 $, 🍊(세번째 input)에는 $ w_3 $ 이 곱해진 후 서로 더해지게 되죠.
구해진 가중합을 $ Z $라고 합시다. 이후 Activation Function(활성 함수)를 거치게 되는데, 앞서 계산한 $Z$값이 특정 Threshold(임계값) 이상이면 1이 출력되고, 이하이면 0을 출력하게 됩니다.
뉴런으로 들어온 정보가 종합된 후, 임계점 이상이면(Activation Function 적용) 1을 다음 뉴런으로 넘긴다는 점이 사람의 뉴런과 비슷하게 느껴지시지 않나요?
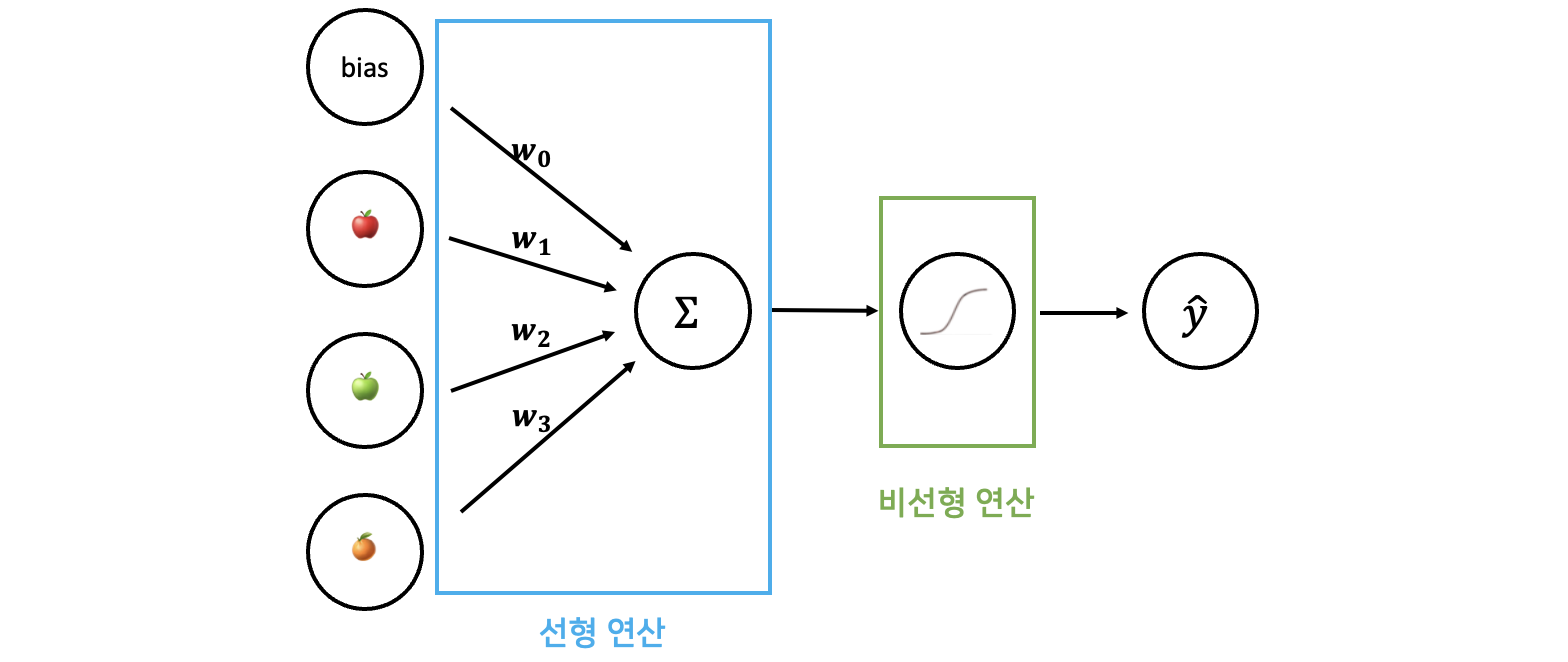
실제 딥러닝에서도 input값에 가중치가 곱해져 가중합이 구해지며, 이 가중합을 활성화 함수(activation function)에 투과시켜 뉴런의 output값을 얻습니다. 가중합을 구하는 “선형” 연산, 그리고 활성화 함수에 해당하는 “비선형” 연산이 함께 존재한다고 볼 수 있습니다.
가중합에서 그치는 것이 아니라 비선형 연산을 적용시키는 이유는 선형함수만 사용한다면 여러 층의 퍼셉트론을 쌓는다 하더라도 하나의 선형 함수에 불과하게 됩니다. 입력값에 따라 결과값이 고르게 변화하는 것이 아닌 불규칙적인 변화를 보이게 함으로써, 여러 층을 쌓았을 때 복잡한 데이터의 특성을 학습할 수 있게 됩니.
Activation Function(활성화 함수)
위와 같은 계단 함수 말고도 활성화 함수로 다양한 함수가 쓰일 수 있습니다.
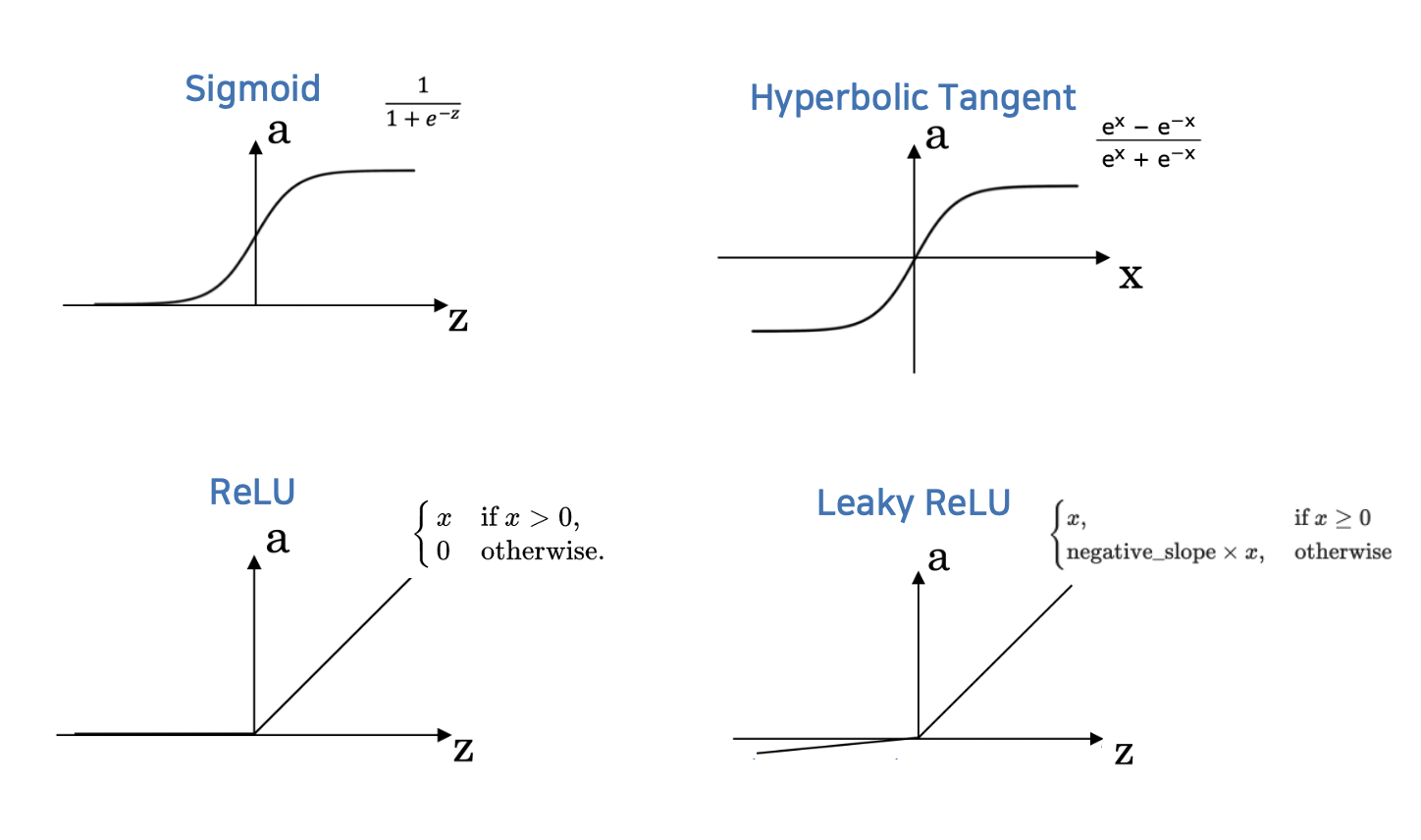
Sigmoid 함수는 x축의 값이 0에 가까울수록 기울기가 크며, x축의 값이 절댓값이 커질수록 기울기가 완만해집니다. 확률값을 출력하는 binary classification을 수행할 시 마지막 layer의 활성화 함수로 주로 사용됩니다. Hyperbolic tangent 함수는 (tanh)라고도 불리며, sigmoid함수와 유사하나 음의 값을 가질 수 있다는 특징이 있습니다.
(그림5)의 아래쪽에 보이는 ReLU함수는 더욱 단순합니다. x축의 값이 음수이면 함숫값이 0이며, 아니면 기울기가 1입니다. ‘과연 이렇게 단순한 함수를 사용하는 것이 비선형 역할을 제대로 할 수 있을까?’라는 의문이 들으실 수도 있습니다. 하지만 ReLU는 가장 많이 쓰이는 활성화 함수 중 하나인데, 그 이유는 sigmoid나 hyperbolic 함수 같은 경우는 x축의 값이 너무 크거나 작으면 0에 가까운 미분값을 얻지만, ReLU는 x축의 값의 절댓값이 커지더라도 어느정도 내성을 갖기 때문에 좋은 효과를 나타냅니다. 또한 미분하기에 단순하기 때문에 연산 시간을 아낄 수 있다는 장점도 있죠. Leaky ReLU는 ReLU의 음수일 때 기울기가 0이라는 단점을 보완한 활성화 함수입니다.
이번 단원을 통해 퍼셉트론 한 개를 거쳤을 때 일어나는 일을 이해하셨을 겁니다. 하나의 퍼셉트론만 보셨을 때는 Regression(회귀)를 한 후 임계치에 따라 판단을 하는 과정에 불과합니다. 하지만 퍼셉트론이 여러 개 모였을 때에는 놀라운 결과를 만들어 낼 수 있습니다. 다음 절을 참고해주세요!
3. 다중 퍼셉트론
퍼셉트론을 하나만 사용했을 때는 좌표명면 상의 데이터를 직선으로밖에 분리하지 못합니다. 아래 (그림6)처럼 말이죠 (2차원 데이터의 선형 분리 예시).
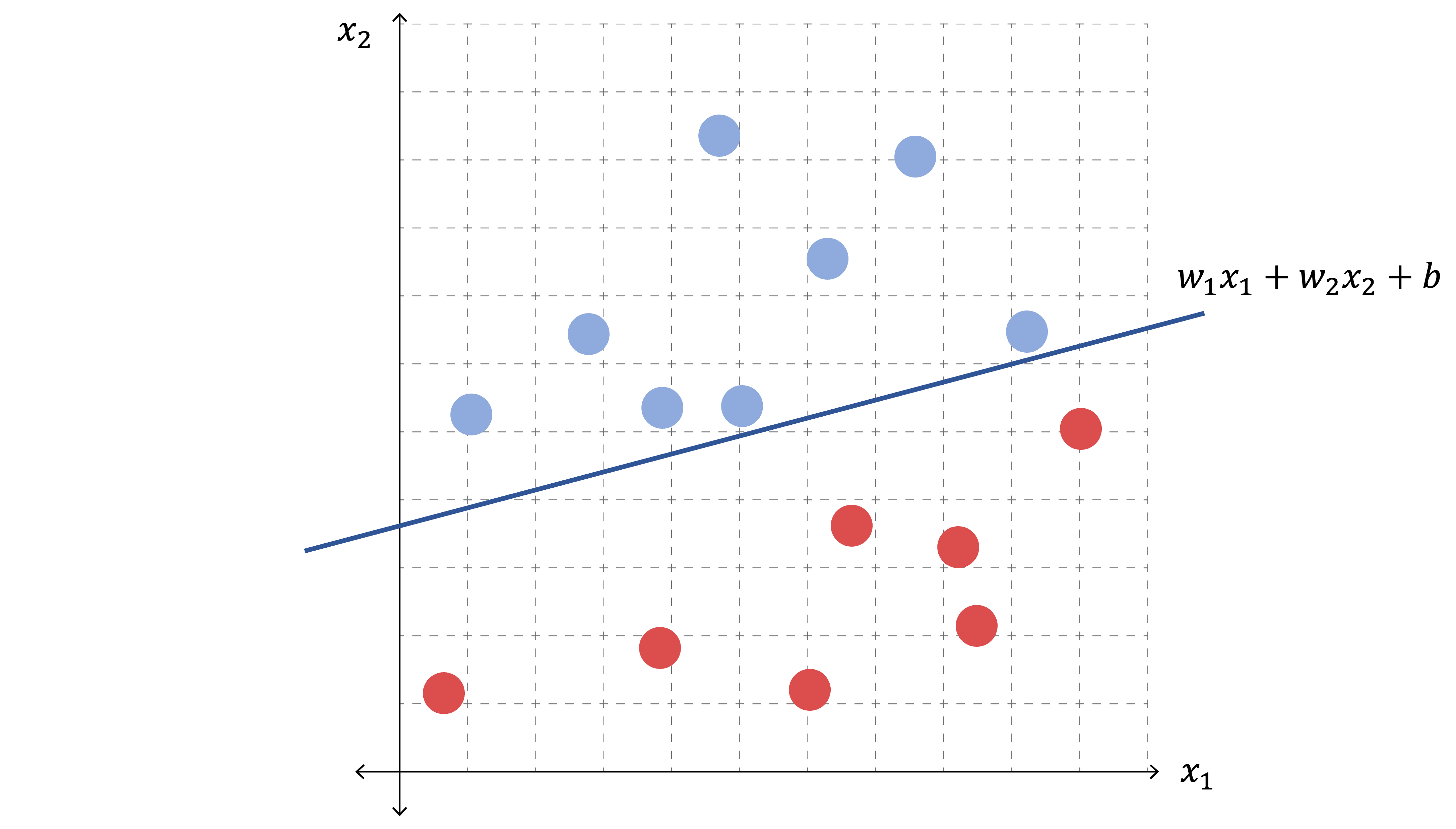
입력값(2차원 좌표)에 따른 결과값(색상)을 직선 형태로밖에 구분하지 못합니다. (예를 들어 직선보다 왼쪽-위에 있으면 파랑, 직선보다 오른쪽-아래에 있으면 빨강)
하지만 한 퍼셉트론에 뒤이어 다른 퍼셉트론을 붙이면, 즉 층(layer)을 더하면 비선형 문제를 풀 수 있습니다.
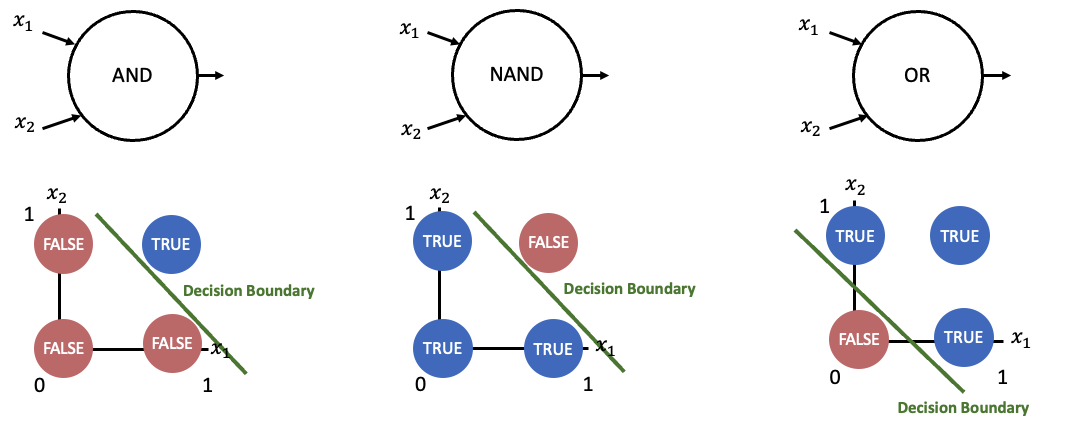
위 그림은 AND, NAND, OR 문제입니다. AND층은 두 입력값이 TRUE일 때 TRUE를 출력하며, NAND(NOT AND)층은 두 입력값이 FALSE일 때 TRUE를 출력합니다. OR층은 두 입력값 중 하나라도 TRUE이면 TRUE를 출력합니다.
이때 입력값 $ x_1 $, $ x_2 $에 대한 결과값을 색상으로 나타내 보았습니다. 결과값이 TRUE인 영역과 결과값이 FALSE인 영역이 “직선”으로 구분 가능함을 알 수 있습니다. 즉, Decision Boundary가 직선입니다.

XOR연산은 두 가지 입력 중 하나만 TRUE일 때만 TRUE이고 아니라면 FALSE인 연산입니다. (그림8)에 표현된 XOR연산의 Decision Boundary를 보면 직선이 아니라 곡선입니다. XOR의 Decision Boundary는 선형적으로 표현이 불가능하기 때문에 하나의 퍼셉트론 층으로는 표현할 수 없습니다.
하지만 첫 층(layer)에 NAND와 OR를 두고 두번째 층(layer)에 AND을 두면서 비선형적인 결과를 만들어내는 XOR 연산을 표현할 수 있게 되었습니다.
퍼셉트론 한 층만으로는 선형 문제밖에 풀지 못했지만, 두 층을 두었더니 더 복잡한 문제를 풀 수 있었습니다. 이처럼 여러 층의 퍼셉트론을 모아 하나의 모델을 구성한 것을 인공신경망(Artificial Neural Network)라고 합니다. 퍼셉트론이 신경세포를 본 뜬 것이니 ‘신경망(Neural Network)’이라는 단어를 선택한 것입니다.
4. 인공신경망 구조
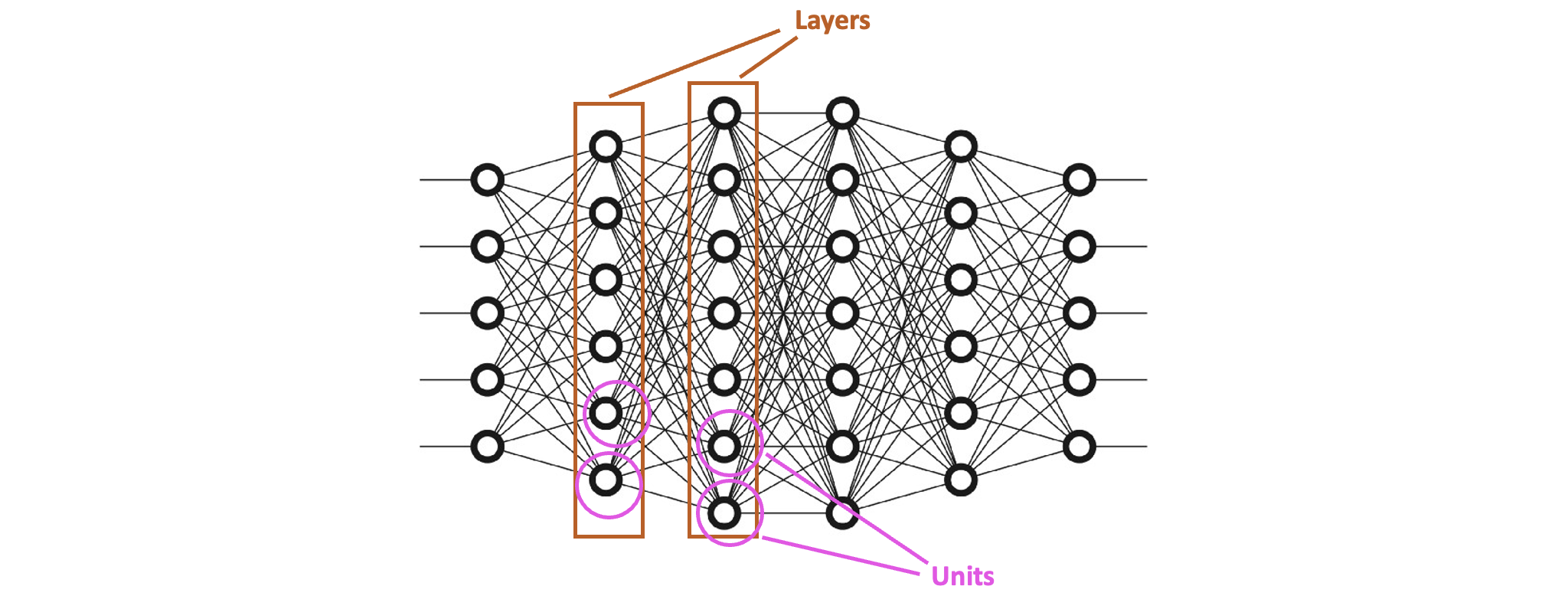
Unit, Node
이제 딥러닝에서 쓰이는 용어로 넘어가도록 합시다. 지금까지 ‘퍼셉트론(perceptron)’이라고 불렀던 하나의 뉴런을 딥러닝에서는 ‘노드(node)’ 또는 ‘유닛(unit)’이라고 부릅니다.
Layer
이전 단원에서 다중 퍼셉트론을 설명할 때 NAND유닛과 OR유닛이 하나의 ‘층’을 이루어고, AND유닛이 하나의 ‘층’을 이루었습니다. 이렇게 한 단계에 존재하는 여러 개의 유닛으로 구성된 ‘층’을 ‘레이어(layer)’라는 용어로 부릅니다.
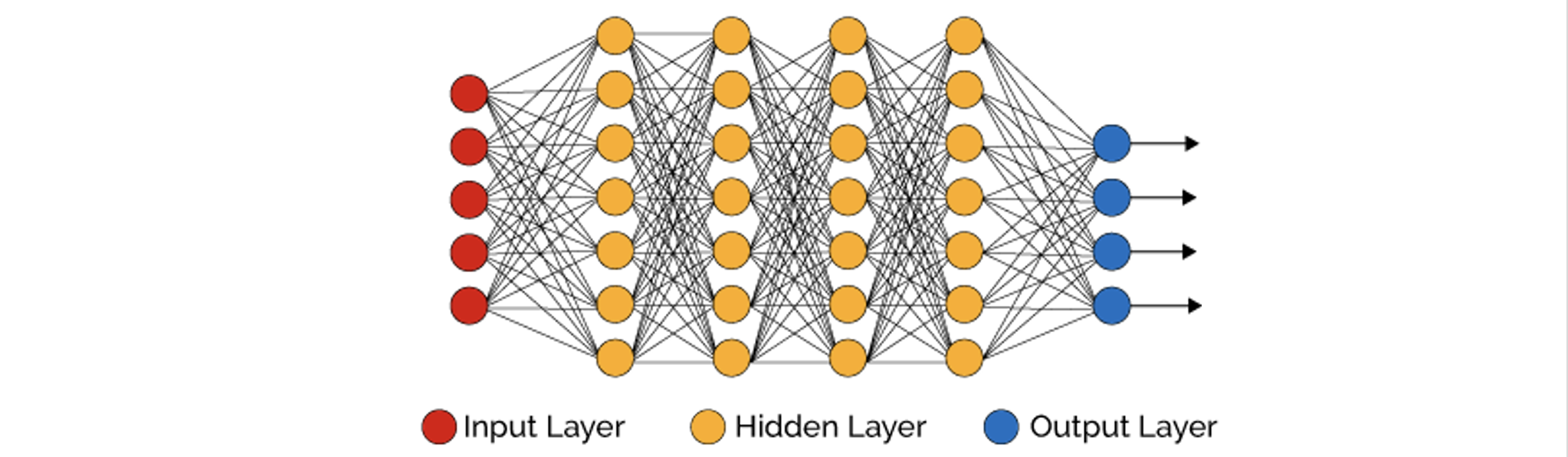
Input Layer, Hidden Layer, Output Layer
Layer는 크게 세 종류로 나눌 수 있습니다. ‘입력층(Input Layer)’, ‘은닉층(Hidden Layer)’, ‘출력층(Output Layer)’으로 말이죠. Input Layer는 네트워크에 들어오는 데이터 그 자체를 지칭합니다.
네트워크로 특정 사람의 ‘[눈 크기, 코 높이, 머리 색상]’ 과 같은 정보가 들어오면 네트워크가 ‘호감’ 또는 ‘비호감’을 판단한다고 합시다. 이때 들어오는 데이터 (예를 들어 [3cm, 1cm, 갈색])가 그 자체로써 Input Layer를 의미합니다. 이때 데이터가 3개 원소로 이루어져 있으니 Input Layer의 노드의 개수는 3개입니다. 최종적으로 ‘호감’ 또는 ‘비호감’이라는 데이터가 출력되는 Layer을 Output Layer라고 합니다.
Input Layer도 아니고 Output Layer도 아닌 모든 Layer들을 ‘Hidden Layer’라고 합니다. 중간 Layer의 이름에 Hidden이라는 용어가 들어간 이유은 무엇일까요? Hidden Layer으로 입력되거나 Hidden Layer에서 출력되는 값은 사람의 입장에서 의미있게 해석되는 값이 아니기 때문에 ‘감춰졌다’라는 표현을 사용합니다.
Layer간 연결의 특징
한 Unit에서는 이전 Layer의 모든 Unit으로부터 정보를 얻어와 계산(Linear Function + Activation) 을 한 후, 그 결과값을 다음 Layer의 모든 Unit으로 전달합니다.
특정 N번째 Layer가 있다고 칩시다. N번째 Layer의 모든 특정 Unit의 출력은 N+1번째 Layer의 모든 Unit으로 전달된다는 특징이 있습니다. 다르게 말해서, N번째 Layer의 개별 Unit 하나하나는 N-1번째 Layer의 모든 Unit으로부터 Input값을 받는다고 할 수 있죠. ((그림9)와 (그림10)을 세심히 관찰해 보시면 무슨 말인지 알 수 있을 거에요.)
Layer간 연결이 의미하는 것
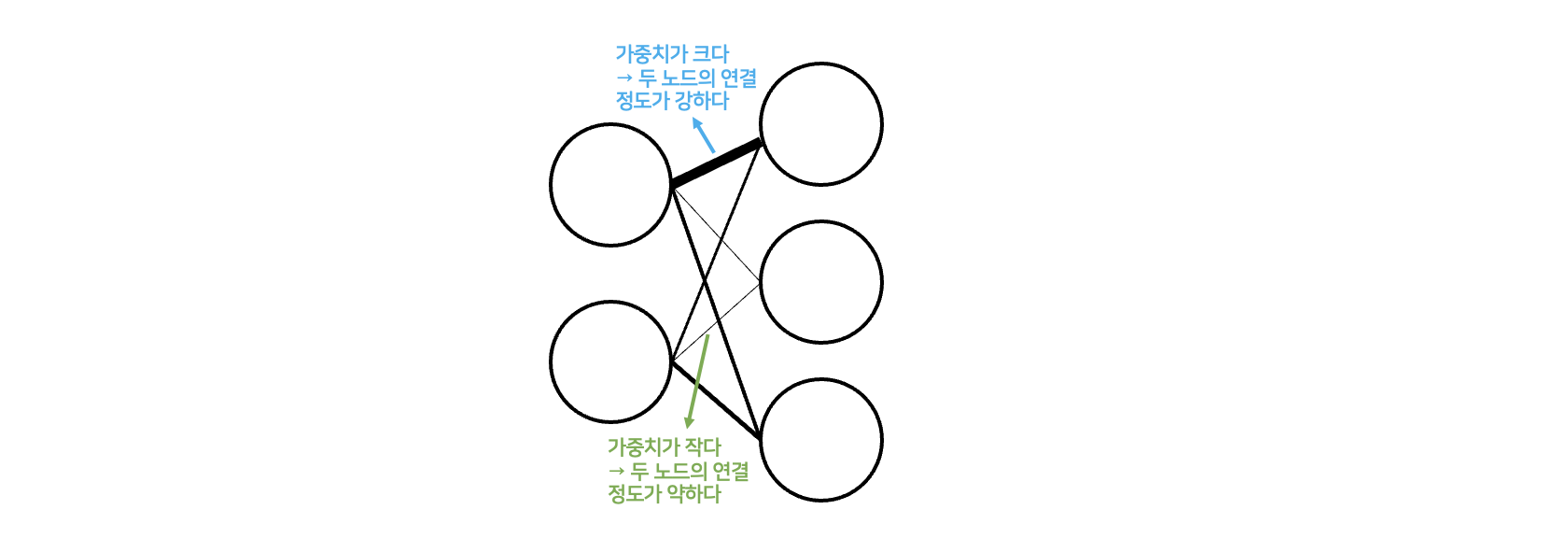
노드 간 연결되는 선분을 ‘가중치(weight)’라고 생각할 수 있습니다. 2단원에서 배웠던 퍼셉트론의 가중치와 같은 의미로써, 특정 노드 기준으로 연결된 이전 노드의 비중이 얼마나 되는지를 나타냅니다. (특정 노드가 내포하고 있는 특성이 이전 노드와 얼마나 관련이 있는지). Training(학습)이 일어나면서 연결의 정도가 큰 노드 사이의 가중치는 점차 커지게 되며, 그렇지 않은 가중치는 작아지게 됩니다.
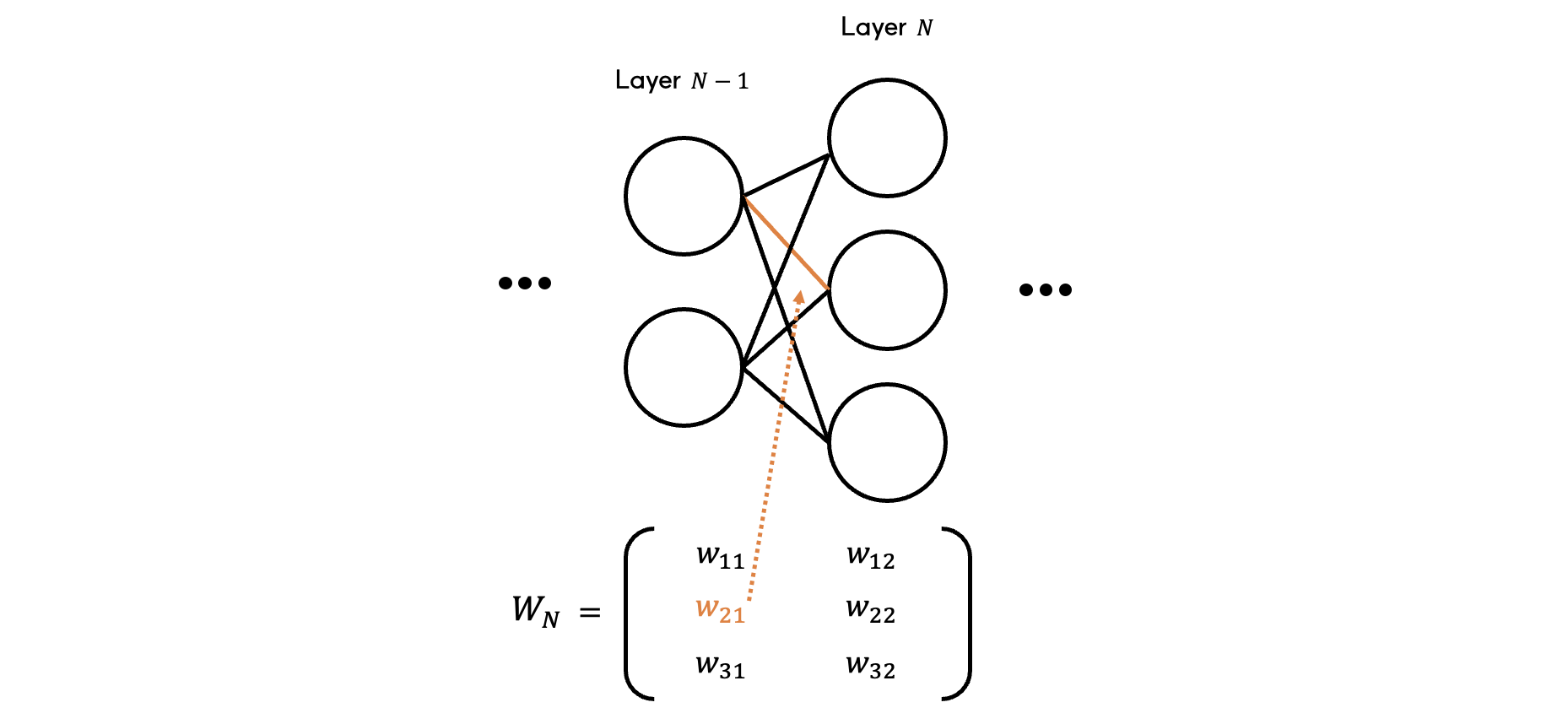
$ N-1 $ 번째 layer과 $ N $ 번째 layer 사이의 모든 가중치를 하나의 가중치 행렬 $ W^{[N]} $ 로 나타낼 수 있습니다. $ i $번 행, $ j $번 열에 존재하는 가중치는 $ N-1 $ 번 layer의 $ j $번째 노드와 $ N $ 번 layer의 $ i $ 번째 노드 사이를 연결하는 가중치입니다.
Layer의 개수
일반적으로 Layer의 개수를 셀 때 input layer의 개수는 포함시키지 않아요. 사실 input layer는 연산을 하는 것이 아니라 네트워크에 주어진 데이터 그 자체이기 때문이죠. 따라서 (그림9), (그림10)의 경우 Layer 개수는 5개라고 할 수 있습니다.
5. 학습이란? 가중치를 조정해 가는 과정이다!
데이터가 어떤 뉴런 하나를 통과하는 것은 이전 layer의 모든 뉴런의 아웃풋에 대한 weighted sum(가중합)을 구한 후 활성화 함수에 대입하는 과정이라고 볼 수 있습니다. 이 때 뉴런의 아웃풋에 영향을 미칠 수 있는 것은 가중치들 입니다. 따라서 ‘학습’이라는 것은 최적의 예측값을 만들도록 각 뉴런의 가중치들을 조정하는 과정입니다. 학습이 진행됨에 따라 weight는 점차 업데이트됩니다. 이렇게 학습이 되는 과정에서 값이 변화하며 모델의 output에 영향을 주는 것을 ‘모델의 파라미터(parameter)’라고도 합니다.
전체적으로 생각을 해 봅시다. Neural Network를 하나의 “함수”라고 생각해 봅시다. 우리가 이 함수에 데이터를 입력하면, 이 함수는 수많은 뉴런을 통과시킨 결과값을 출력합니다. 이때 예측값을 정확하게, 즉 실제값과 비슷하게 출력하도록 만드는 것이 우리의 목표입니다.
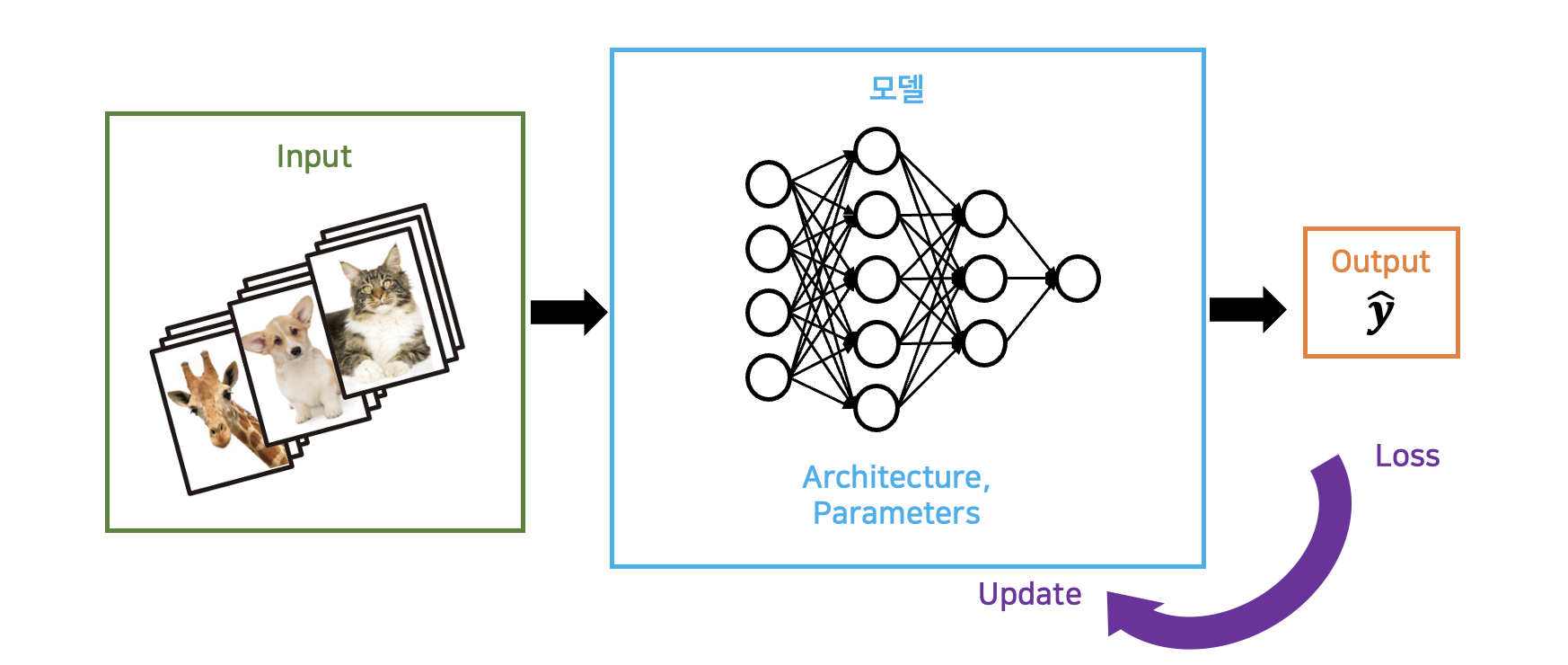
우리는 수많은 데이터(training set)를 가지고 학습을 진행합니다. 데이터들이 라벨링되어 있다고 해 봅시다. input값에 대한 라벨(ground truth)이 쌍으로 존재합니다. Input값을 모델에 대입하면 모델은 정해진 구조(architecture)에 분포된 파라미터에 의해 계산된 예측값을 출력합니다. 이 예측값이 해당 데이터의 실제 ground truth와 얼마나 가까운지 측정합니다. (오차(loss)를 계산합니다). 이 loss를 기반으로 모델을 구성하는 파라미터들을 업데이트할 수 있습니다. 이 과정이 한번 반복되었을 때 iteration이 한번 수행되었다고 합니다.
그렇다면 파라미터 어떻게 업데이트 되는 것일까요? 현재 weight들에 대한 loss의 “변화율”에 기반하여 weight들을 업데이트 해나갑니다. 이러한 반복이 진행되면 진행될수록 weight들은 더 낮은 loss를 갖는 예측값을 출력하도록 변화하게 됩니다. 이후 내용에서 설명이 이어집니다.
Deep Learning이라는 용어의 뜻은 어렵게 이해할 필요가 없어요. “Deep” 하다는 것은 layer가 여러 겹 있다는 뜻이고, “Learning” 은 그 상태에서 각 layer의 파라미터들을 업데이트해가며 학습을 한다는 것입니다!
6. Forward-propagation
5단원에서 딥러닝에서 ‘학습’이라는 것이 무엇인지 배웠습니다. 이번 단원부터 학습이 일어나는 과정을 한가지 예시와 함께 조금 더 자세히 살펴보도록 해요.
연예인의 ‘키’, ‘몸무게’, ‘눈 크기’, ‘코 높이’ 를 갖고 ‘호감 여부’를 예측하는 모델을 만들고 싶습니다. 이 때 학습을 위한 데이터셋은 아래와 같이 주어졌습니다.
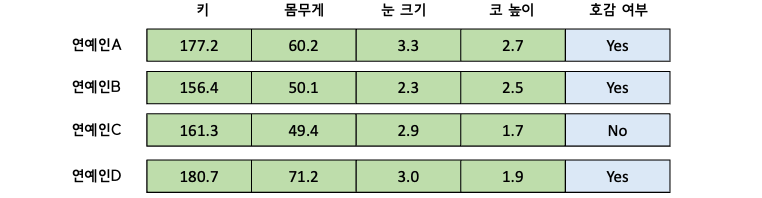
위 데이터에서 호감 여부는 라벨이므로 따로 $ y $ 로 분리하고, 나머지 4개의 input data를 행렬 $ X $ 로 표현해 보면 아래와 같습니다.
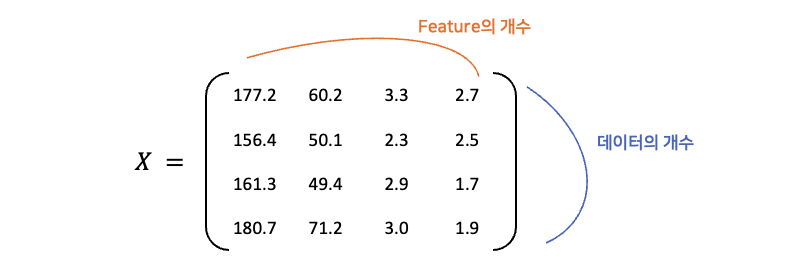
$ X $ 의 행의 수는 iteration에 사용할 데이터의 수이며, 열의 수는 특성(feature)의 수 입니다.
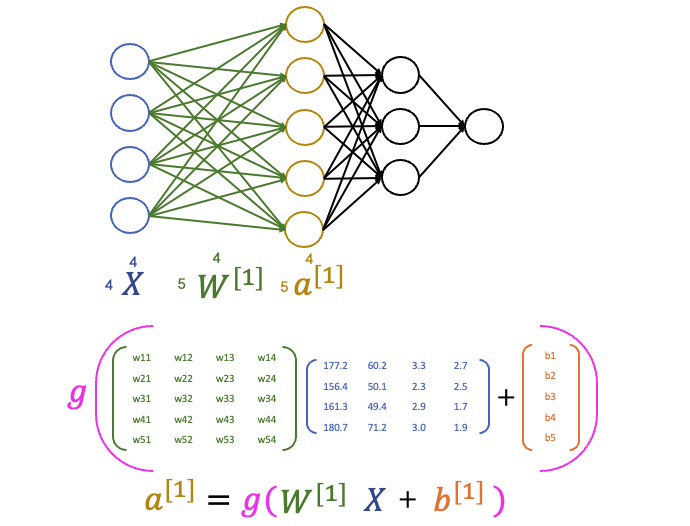
첫번째 layer를 통과해 보겠습니다. 첫 layer의 가중치 행렬 $ W^{[1]} $ 에 input 행렬 $ X $ 이 곱해지며, 각 행에 대응하는 bias 벡터 $ b^{[1]} $ 의 값이 더해집니다. (굳이 bias라는 것을 두어 이를 더하는 이유에 대해서는 아래에 설명하였습니다). 여기까지 수식으로 나타내면 $ Z^{[1]} = W^{[1]}X + b^{[1]} $ 입니다.
이제 $ Z^{[1]} $ 을 activation function(활성화 함수)에 통과시키면 첫번째 layer의 아웃풋을 얻을 수 있습니다. 이를 수식으로 표현하면 $ a^{[1]} = g(Z^{[1]}) $ 입니다.
첫 layer의 계산을 마쳤습니다. 한가지 주목할 점은, 행렬 곱셈을 사용하였기에 layer의 모든 노드의 계산을 한번에 진행할 수 있었다는 점입니다.
이후 layer에 대해서도 똑같습니다. 임의의 layer $ N $ 의 연산을 일반화하면 아래와 같습니다.
\[Z^{[n]} = W^{[n]} a^{[n-1]} + b^{[1]}\] \[a^{[n]} = g(Z^{[n]})\]$ a^{[n]} $ 는 $ n $ 번째 layer의 아웃풋을 의미합니다. 일반화를 위해 input data $ X $ 를 $ a^{0} $ 으로 정의하였습니다.
$ W^{[n]} $ 는 $ n $ 번째 layer의 가중치 행렬입니다. ($ n-1 $ 번과 $ n $ 번 layer를 연결하는 선분으로 생각해주세요.)
$ Z^{[n]} $ 는 $ n $ 번째 layer에서 선형 연산(가중치합)까지 수행한 결과물이며, $ g $ 는 활성화함수(activation function)을 의미합니다.
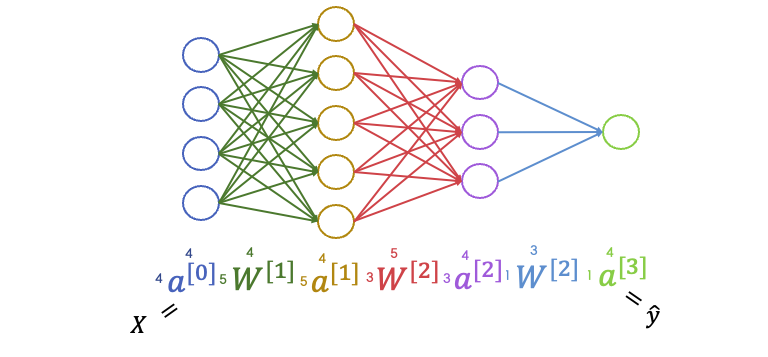
전체 layer를 통과하면 1행 4열짜리 $ \hat{y} $ 벡터를 얻게 됩니다. 우리의 데이터셋에 적용하면, 4명 연예인 각각에 대한 호감으로 판단할 확률을 예측한 것입니다. 한 연예인당 예측값이 ‘호감 확률’ 한 가지이므로 마지막 output layer의 노드는 한 개입니다.
행렬의 사이즈를 계산하는 Tip
(그림17)을 보면 네트워크 구조에 따른 가중치 행렬의 크기와 데이터 행렬의 크기가 표현되어 있습니다. 이러한 행렬의 크기(행의 수, 열의 수)는 어떻게 파악한 것일까요?
-
데이터 행렬($ a $) 의 열의 수는 항상 ‘iteration에 입력 벡터의 샘플의 수’입니다. 우리는 연예인 4명을 iteration에 사용했으므로 전체 네트워크에서 $ a $ 의 열의 수는 항상 4인 것을 확인할 수 있습니다.
-
데이터 행렬($ a $)의 행의 수는 해당 layer의 노드의 개수입니다. 예를 들어 1번 layer의 노드는 5개였으므로 $ a^{[1]} $ 의 행은 5개입니다.
-
가중치 행렬 ($ W $)의 열의 수는 “이전 layer”의 노드의 개수입니다.
-
가중치 행렬 ($ W $)의 행의 수는 “현재 layer”의 노드의 개수입니다.
Bias를 사용하는 이유
각 $ n $ 번째 layer마다 layer내 뉴런의 개수 만큼의 크기를 갖는 bias 벡터 $ b^{[n]} $ 가 존재합니다. 단순히 가중합을 구해서 비선형 activation에 넘겨주는 것이 아니라, 가중합에 bias가 더해져서 $ W^{[n]}a^{[n-1]} + b $ 형태가 만들어진 후 넘겨지죠. Bias 벡터도 weight 행렬과 마찬가지로 학습이 진행되며 값이 업데이트됩니다. Weight 뿐 아니라 bias를 사용하는 이유는 무엇일까요?
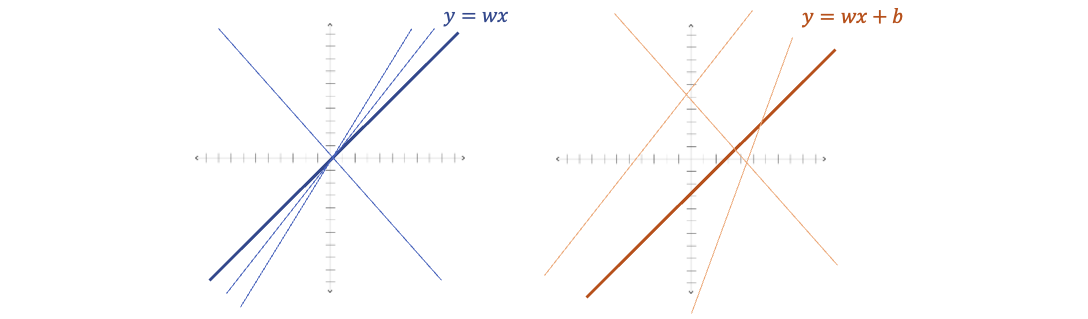
(그림18)의 왼쪽은 $ y = wx $의 그래프입니다. 표현할 수 있는 대응관계는 $ w $ 값에 따라 기울기만 다르고 원점을 지나는 직선 형태입니다. 오른쪽은 $ y = wx + b $의 그래프입니다. 원점을 지나지 않는 그래프도 표현할 수 있게 되었죠.
이처럼 선형결합에 상수항을 추가하므로써 원점을 지나지 않는 $ x $ 와 $ y $ 의 대응 관계도 표현할 수 있습니다. 결과적으로 각각의 노드에서 decision boundary를 더 정확하게 표현할 수 있게 된다는 효과가 있습니다.
7. Gradient Descent와 Optimization
5단원에서 딥러닝에서 ‘학습’이란 loss를 최소화 하기 위해 파라미터를 업데이트해 가는 과정이라고 배웠습니다. 이렇게 모델이 최선의 아웃풋을 출력하도록 만드는 것을, 우리는 모델을 최적화(optimize)한다고 합니다. 그렇다면 optimize하기 위해서 파라미터는 어떻게 업데이트를 하는 것일까요? 이 방법을 배우기 위해 우선 weight에 대한 loss의 그래프가 있다고 가정해 봅시다.
Convex Function
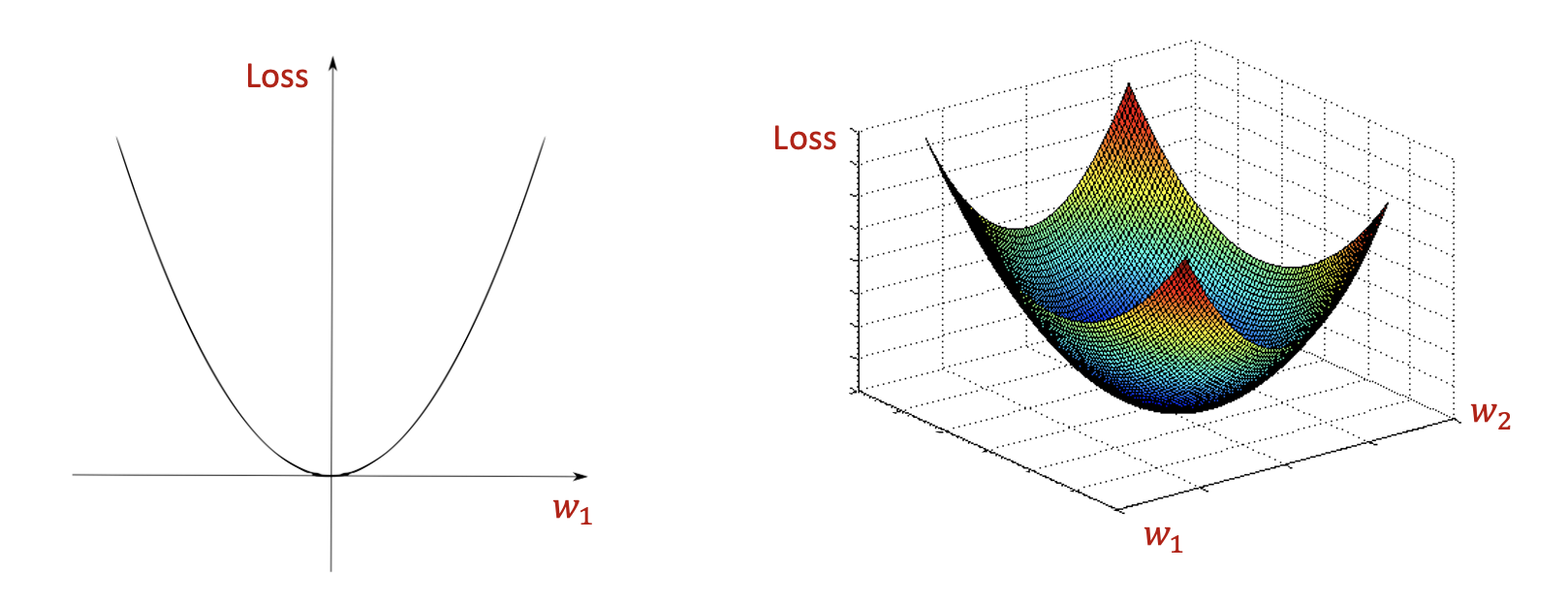
볼록 함수(convex function)에 대해 들어 보셨나요? 우리가 가장 잘 convex function은 이차함수 입니다. 함수가 최솟값을 가지게 하는 특정 x값이 존재하는 것이 특징입니다.
우리의 목표는 loss를 최소로 하는 weight를 찾는 것입니다. Weight에 대한 loss의 함수가 (그림19)과 같이 convex function이라고 해 봅시다.
그렇다면 (그림19)의 왼쪽 그림인 2차원 함수의 경우 가장 볼록한 지점에 loss값이 최소가 되도록 하는 weight값이 존재하게 되며, (그림19)의 오른쪽 그림인 3차원 함수의 경우에도 가장 볼록한 지점에 loss값이 최소가 되도록 하는 weight값 쌍이 존재하게 됩니다.
파라미터를 움직이기

그렇다면 loss가 최소가 되기 위해서는 weight를 어떻게 움직이는 것이 좋을까요? (그림20)의 왼쪽 2차원 그래프를 봅시다. $ w_1 $ 이 0일 때 loss가 최솟값이 되죠. $ w_1 $이 0보다 작은 상황이면, $ w_1 $ 값을 오른쪽(더 커지게)으로 업데이트하고 $ w_1 $ 이 0보다 큰 상황이라면 왼쪽으로(더 작아지게) 업데이트하면 되겠죠?
이것을 구현하려면 어떻게 하면 될까요? “기울기(의 상수곱)를 빼는 과정”을 통해 $ w_1 $ 값을 볼록점의 $ w_1 $ 값으로 모이게 할 수 있습니다.
$ w_1 $ 값이 0보다 작다면, 양수를 더해야 0으로 모이게 할 수 있습니다. 이때 $ w_1 $ 에서 loss함수의 기울기가 음수이기 때문에 이 ‘음수 상태인 기울기’를 빼는 것이 양수를 더하는 것과 같은 효과를 얻습니다.
$ w_1 $ 값이 0보다 크다면, 양수를 빼야 0으로 모이게 할 수 있습니다. 이때 $ w_1 $ 에서 loss함수의 기울기가 양수기 때문에 이 기울기를 빼는 것으로 $ w_1 $ 값을 0(볼록점의 $ w_1 $ 값)으로 모이게 할 수 있습니다.
이렇게 loss가 최소가 되도록 하는 파라미터 값들을 “optimal point”라고 합니다.
(그림20)의 왼쪽 그림은 neural network에서 weight가 하나일 때 loss의 그래프를 나타낸 것이라면, (그림20)의 오른쪽 그림은 weight가 두 개일 때 loss의 그래프를 나타낸 것입니다. 이 때 $ w_1 $ 도 optimal point으로 옮기고 $ w_2 $ 도 optimal point으로 옮길 필요성이 있습니다. $ w_1 $ 값도 기울기를 빼고 $ w_2 $ 도 마찬가지로 기울기를 빼는 과정을 통해 $ w_1 $ 와 $ w_2 $ 를 각각 optimal point으로 수렴시키면 됩니다.
실제로 neural network에서의 weight의 개수는 한개도 아니고 두개도 아닙니다. 각 layer마다, 그리고 각 unit마다 여러 개의 weight가 존재하며, 때로는 수천개가 되기도 합니다. 2차원, 3차원의 그래프는 그릴 수 있지만 수천 차원의 그래프는 그릴 수 없습니다. 하지만 그 때도 이렇게 각 weight마다 “본인에 대한 loss의 변화율”을 뺌으로써 optimize를 수행할 수 있다는 것은 똑같이 적용됩니다.
Gradient
특정 weight에 대한 loss function의 기울기를 ‘gradient’라는 용어로 지칭합니다. Gradient는 해당 변수에 대한 편미분으로 표현되죠. 예를 들어 함수 $ f(x,y) $ 에서 $ f $ 의 기울기를 구하고 싶을 때, $ x $ 에 대한 $ f $ 의 변화율($ {∂f} \over {∂x} $), $ y $ 에 대한 $ f $ 의 변화율($ {∂f} \over {∂y} $)을 구할 수 있죠. 딥러닝에서로 치환해 보면 $ x $ 와 $ y $ 는 모델을 구성하는 파라미터이며 $ f $ 는 $ x, y $에 대한 loss 로 볼 수 있습니다. 하지만 6단원에서 보았듯이, 딥러닝의 neural network에 파라미터가 두개는 아니며 수많은 개수가 존재합니다. $ W^{[1]}, W^{[2]}, W^{[3]}, … $ 이런 식으로 가중치 행렬이 있으며 각 행렬에는 해당 layer의 가중치들이 포진되어 있죠. 여러 layer로 이루어진 neural network에서 각 파라미터의 편미분값을 어떻게 구하는지는 다음 포스팅에서 설명하겠습니다. 결과적으로, 우리는 매 iteration마다 이 수많은 파라미터에다가 ‘해당 파라미터의 gradient에 일정 learning rate를 곱한 값’을 빼주는 작업을 수행하여 모델을 optimize(최적화)해 나갑니다.
Gradient Descent(경사하강법)
위 수식과 같이 매 iteration마다 파라미터의 gradient를 차감해 주는 과정을 gradient descent라고 합니다. 차감되는 변화율 앞에 붙은 $ \alpha $ 는 learning rate(학습률)로써, 한꺼번에 얼마나 내려갈지를 결정합니다. Learning rate 값을 키운다면 더 적은 iteration에 걸쳐 빠르게 최적화 할수 있지만, 정교한 방향으로 움직이지 못하게 되며 마지막 optimal point에 가까워졌을때 진동하게 될 가능성이 커집니다.
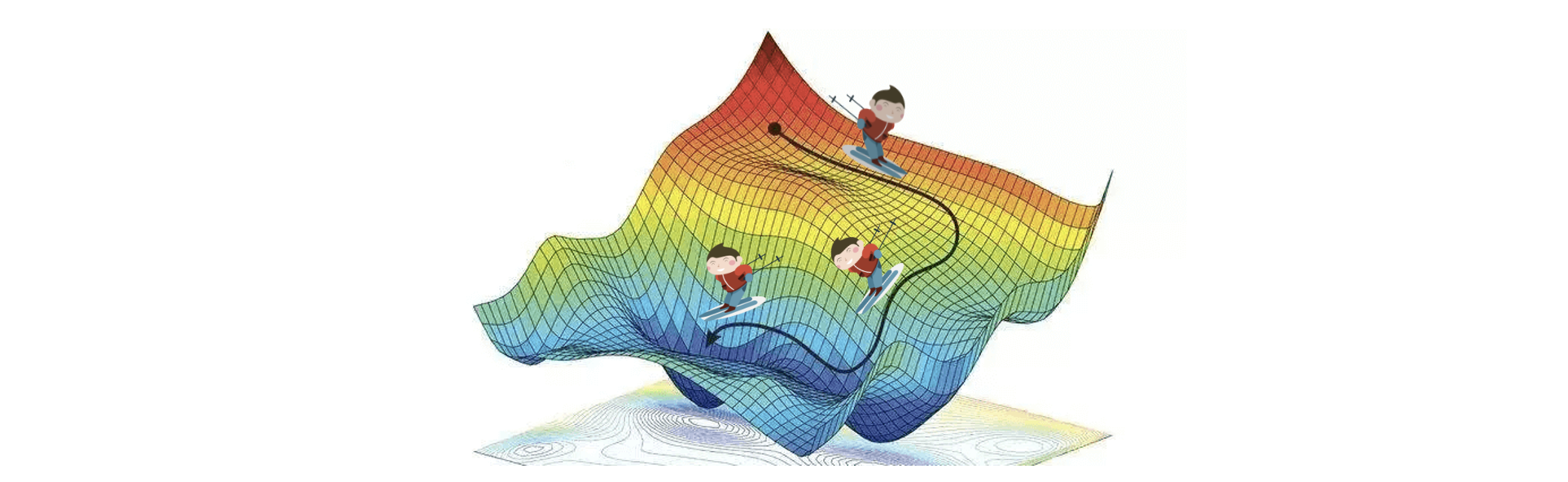
Gradient descent를 다르게 해석하면 파라미터에 대한 loss의 그래프에서, 그때 그때 시점에서 가장 가파른 기울기로 내려간다고 생각해 볼 수 있습니다. (그림21)에서 가장 가파른 경사로만 스키를 타는 사람처럼, 전체적인 과정을 고려하지 않고 해당 시점(해당 iteration)에서의 최선의 방향으로 최적화를 진행해 나가는 것이죠.
Local Minimum
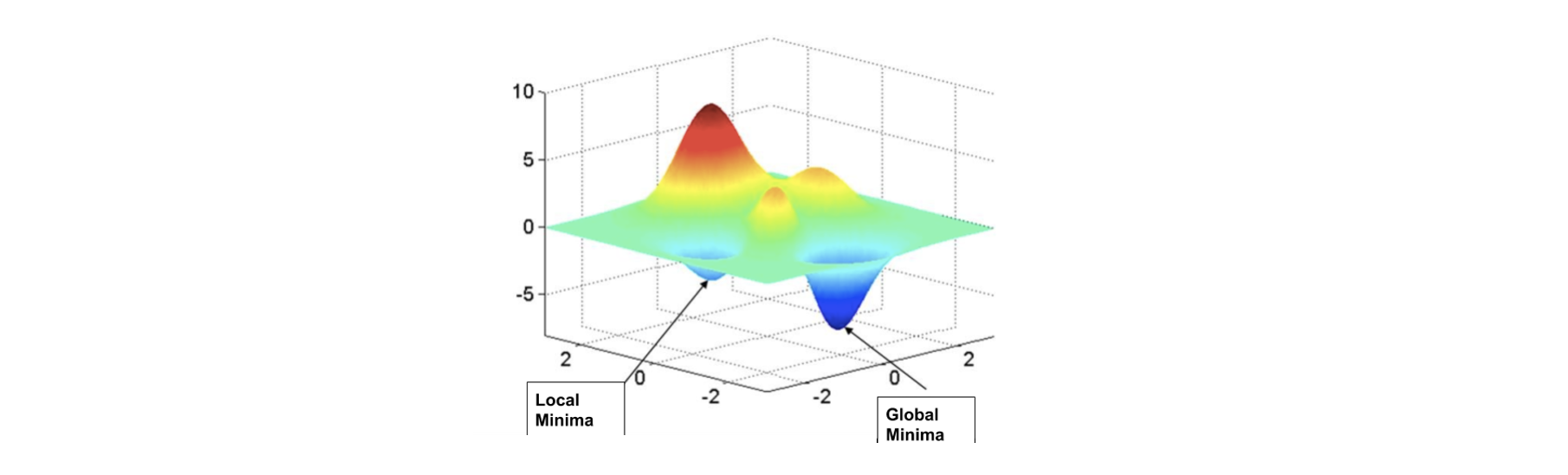
이와 같은 gradient descent 과정을 통해 optimal point를 찾기 위해서는, 우리가 처음에 전제로 했던 볼록함수(convex function)여야 한다는 것이 필요조건입니다. 이렇게 그때 그때 가장 가파른 길로 내려갔더니 전체 구간에서의 최솟값(global minimum)이 아닌 부분 구간에서의 최솟값(local minimum)에 수렴하게 만들 위험도 있습니다. 아래 (그림22)처럼 말이죠. 이렇게 함수 전체 구간에서의 최솟값이 아닌 부분 구간에서의 최솟값으로 optimize되는 현상을 “local optima problem”이라고 합니다.
하지만 현재로써는 이 문제를 고려할 필요가 없다는 것이 중론입니다. Local minimum을 찾지 못하더라도, 딥러닝에서의 weight처럼 변수의 개수가 충분히 많아진다면 성능이 좋게 나오는 경우가 많기 때문입니다.
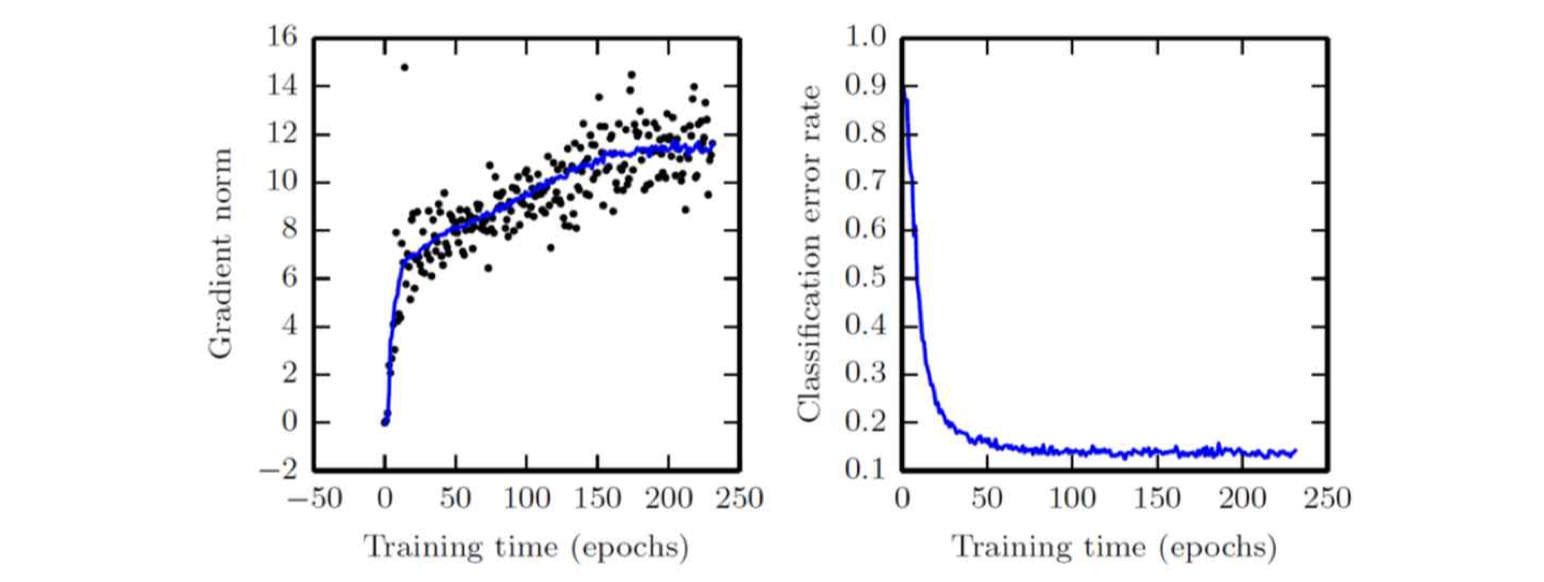
위 그래프를 보시면 iteration이 반복할 때 gradient norm이 증가하지만(실제 optimal point와 멀어지고 있다는 것을 의미합니다) error rate는 감소하는 것을 확인하실 수 있습니다. (모델이 우리가 시키는 task를 잘 수행하고 있다는 것을 의미합니다.)
8. 정리하자면..
- 우리의 목표는 neural network가 정확한 예측값을 출력해 내도록 학습 시키는 것이며, ‘학습’은 neural network상에 존재하는 parameter를 업데이트함으로써 진행됩니다.
- 데이터셋을 neural network에 집어넣어 예측값을 얻고, ground truth와 예측값을 비교하여 loss를 얻는 과정을 forward-propagation이라고 합니다.
- 각 parameter들에 대한 loss의 변화율인 gradient들을 구한 다음 parameter에 gradient에 learning rate를 곱한 값을 빼 parameter값을 업데이트합니다. (Optimization)
- 이를 위해 여러 layer에 걸쳐 (loss에서 첫번째 layer 방향으로) gradient를 계산하는 방법을 back-propagation이라고 하는데, 다음 포스팅에서 설명하도록 하겠습니다.
- Forward-propagation, loss 계산, back-propagation을 모두 거치면 1회의 iteration이 일어났다고 할 수 있습니다.
- Iteration 과정이 수천 번, 수만 번, 또는 그 이상으로 반복시켜 학습을 진행시킵니다. 점점 loss가 작은 예측값을 출력하는 딥러닝 모델이 만들어집니다.
이상으로 이번 포스팅을 마치겠습니다. 끝까지 읽어주셔서 감사합니다^^
댓글남기기